MIT发布《人工智能加速器》2022年度综述论文,详解80+类AI芯片性能优劣与公共数据之关键角色
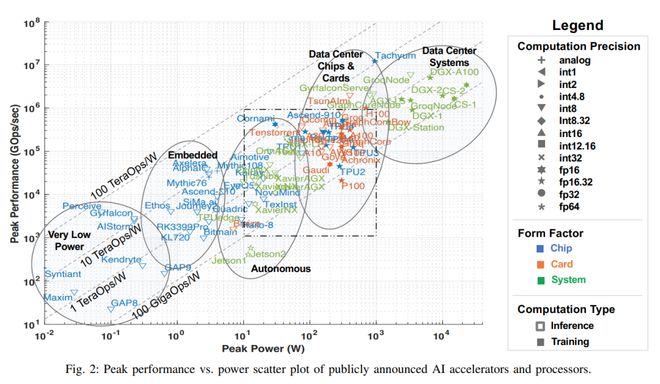
麻省理工学院(MIT)发布了备受瞩目的《人工智能加速器》2022年度综述论文。这份报告不仅系统性地梳理和分析了超过80类人工智能芯片的性能优劣、架构特点与应用场景,还深入探讨了人工智能公共数据在推动AI硬件发展与优化中的核心作用,为学术界与工业界提供了宝贵的参考与洞察。
在AI技术飞速发展的当下,专用加速器芯片已成为提升计算效率、降低能耗的关键。MIT的综述论文覆盖了从云端训练到边缘推理的广泛芯片类型,包括GPU、TPU、FPGA以及各类ASIC定制芯片。报告通过统一的基准测试与性能指标,对这些芯片的算力(如TOPS)、能效比(每瓦特性能)、内存带宽、延迟以及编程灵活性进行了横向对比。分析指出,尽管通用GPU在生态和灵活性上仍占优势,但针对特定算法(如Transformer、CNN)优化的专用ASIC在能效和峰值性能上表现更为突出,尤其是在数据中心和大规模部署场景中。专用化也带来了更高的设计成本与较长的开发周期,其适用性高度依赖于目标工作负载的稳定性和规模。
值得注意的是,报告特别强调了评估芯片性能时,脱离实际应用与数据环境进行孤立比较的局限性。芯片的优劣并非绝对,而是高度依赖于它所运行的人工智能模型、算法以及——至关重要的是——所处理的数据特性。这正是人工智能公共数据价值凸显之处。
人工智能公共数据:芯片性能评估与优化的基石
论文指出,高质量、标准化、可公开获取的数据集对于AI芯片的公平评估、架构创新与驱动优化至关重要。
- 提供公平、可复现的基准测试环境:多样化的公共数据集(如图像分类中的ImageNet、自然语言处理中的GLUE基准、语音识别中的LibriSpeech等)为不同AI加速器提供了统一的“赛道”。研究人员和开发者可以在相同的数据和任务上测试芯片,从而获得可比性强的性能数据(如吞吐量、准确率、功耗),客观揭示各芯片架构在处理不同类型数据负载(如密集矩阵计算、稀疏数据处理、序列建模)时的长处与短板。没有这些公共数据,性能宣称就容易陷入“各自为政”、难以验证的境地。
- 驱动芯片架构的针对性设计:公共数据集中蕴含的典型工作负载模式和数据特征(如数据复用性、稀疏性、精度要求)直接指导着芯片设计。例如,面对视觉数据常用的卷积运算,芯片设计会优化卷积单元和片上内存层次;而处理自然语言序列数据,则可能强化注意力机制的相关计算单元。分析80多类芯片可以发现,许多新兴加速器正是针对特定领域(如自动驾驶、科学计算)的公共数据集所代表的任务进行深度优化,从而实现了性能的飞跃。
- 促进软硬件协同优化:优秀的AI加速器需要配套的编译器、算子库和软件栈来充分发挥硬件潜力。公共数据集为这些软件工具的开发和优化提供了标准化的目标。芯片厂商和社区可以基于公共数据训练的代表性模型,持续优化其驱动程序和运行时,确保硬件能力能被高效、便捷地调用,从而降低开发者的使用门槛,提升整个技术栈的效率。
- 加速研究创新与生态构建:公开的基准数据和性能结果促进了学术界的开放式研究,使得新的架构思想(如存内计算、近似计算、新型数值格式)能够被快速验证和迭代。它也为产业界在选择技术路线、进行供应链决策时提供了关键依据,有助于健康竞争生态的形成,最终推动AI计算成本的下降和技术的普及。
结论与展望
MIT的这份综述论文清晰地表明,AI芯片的竞赛已从单纯的算力追逐,进入到以能效比、实际任务性能和总体拥有成本为核心的综合能力比拼阶段。在这场竞赛中,人工智能公共数据扮演着“裁判员”、“教练员”和“方向标”的多重角色。随着AI应用场景的不断细分(如生物计算、量子机器学习),对更多样化、更专业化公共数据集的需求将愈发迫切。如何构建能更好反映真实部署环境(包括数据流、隐私安全要求)的评估基准,也将是学界和业界需要共同努力的方向。
《人工智能加速器》2022年度综述不仅是一份详尽的芯片性能“体检报告”,更是一次对AI计算基础设施全栈——从底层硬件到顶层数据与算法——协同发展重要性的深刻阐述。它提醒我们,在关注芯片算力数字的必须重视那些驱动并衡量这些算力的、不可或缺的公共数据资源。
如若转载,请注明出处:http://www.91qianmei.com/product/5.html
更新时间:2026-03-08 17:28:24